
TensorFlow recently launched its first 3D model in TensorFlow.js pose detection API. The new model opens up doors to new design opportunities for applications such as fitness, medical motion capture, entertainment, etc.
Here is an example of 3D motion capture, which drives an animated character in the browser. Click here to try it out.
Register for our upcoming AI Conference>>

Powered by MediaPipe and TensorFlow.js, this community demo uses multiple models, including FaceMesh, BlazePose, and HandPose. Try out the live demo here.
Pose detection is one of the most critical steps in understanding the human body in videos and images. Previously, TensorFlow supported 2D pose estimation. The source code for pose detection is available on GitHub. Currently, it is available in three models, namely MoveNet, MediaPipe BlazePose, and PoseNet.
MoveNet is an ultra-fast and accurate model that detects 17 keypoints of a body and can run on laptops and phones at 50+ fps. MediaPipe BlazePose can detect 33 keypoints, in addition to the 17 COCO keypoints, and provides additional keypoints for the face, hands, and feet. In PoseNet, each pose contains 17 keypoints, and can detect multiple poses.
A Deep Dive into the 3D Pose Detection Model
One of the critical challenges the researchers encountered while building the 3D part of their pose model was obtaining realistic, in-the-wild 3D data. In comparison, the 2D pose model is obtained via human annotation.
However, obtaining accurate manual 3D annotation requires either a lab setup or specialised hardware with depth sensors for 3D scans, which introduces additional challenges to preserve a good level of human and environment diversity in the dataset.
Further, many researchers tend to use another alternative to build a completely synthetic dataset to address this challenge. That, again, leads to another challenge of domain adaptation to real-world pictures.
TensorFlow has used a statistical 3D human body called GHUM, developed using a large corpus of human shapes and motions. “To obtain 3D human body pose ground truth, we fitted the GHUM model to our existing 2D pose dataset and extended it with real-world 3D keypoint coordinates in metric space,” said the TensorFlow team.
During the fitting process, the team said that the shape and the pose variable of GHUM were optimised such that the reconstructed model aligns with the image evidence. It included 2D keypoint and silhouette semantic segmentation alignment, and shape and pose regularisation terms.

Here’s how it’s done
Due to the nature of 3D to 2D projection, multiple points in 3D can have the same projection in 2D. Therefore, the fitting can result in several realistic 3D body poses for the given 2D annotation. To reduce this ambiguity, the annotators were asked to provide depth order between pose skeleton edges where they are certain, as shown in the image below.

Compared to real depth annotation, this task proved to be an easy one for them. It showed high consistency between annotators and helped reduce the depth ordering errors for the fitted GHUM reconstructions from 25 per cent to 3 per cent.
Thanks to BlazePose GHUM, it utilises a two-step detector-tracker approach where the tracker operates on a cropped human image. Hence, the model is trained to predict the 3D body pose in relative coordinates of a metric space with origin in the subject’s hips.
MediaPipe vs TensorFlow.js
When choosing MediaPipe versus TensorFlow.js, there are some pros and cons of using each runtime. According to the team, the MediaPipe runtime offers faster inference speed on desktop, laptop, and Android phones. TensorFlow.js, on the other hand, provides faster inference speed on iPhones and iPads. Tf.js runtime is also about 1 MB smaller than the MediaPipe runtime.
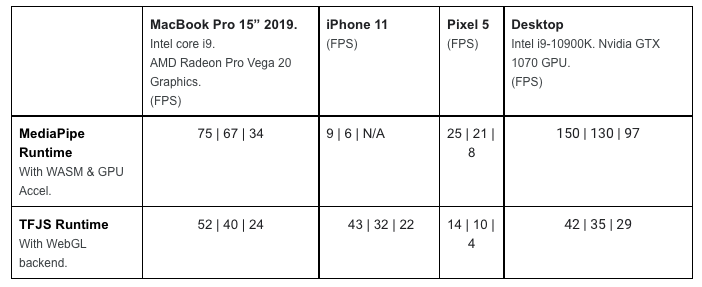
(Source: TensorFlow)
The above table represents the performance of MediaPipe and TensorFlow.js runtime across different devices. The first number in each cell shows the lite model, followed by the second number for the full model and the third for the heavy model, respectively.
Join Our Discord Server. Be part of an engaging online community. Join Here.
Subscribe to our Newsletter
Get the latest updates and relevant offers by sharing your email.
social experiment by Livio Acerbo #greengroundit #thisisnotapost #thisisart